This post will be a high-level overview of the main ideas behind the paper, Generative Modeling via Drifting.
Setup
Generative modelling can be formulated as learning a function that maps a known prior distribution to a target distribution (usually the data itself) .
Let's assume that the prior distribution is a standard Gaussian (standard in the generative models) and the target distribution is the data distribution. Since training a neural network via gradient descent is inherently an iterative process, it's reasonable to assume that during training, we'd have access to a function that maps to , which is our approximation to at iteration . So, for each iteration, there is a "drift" between a sample at the -th iteration and that at the -th iteration. We can write:
where
If , we have reached an equilibrium point where it doesn't make sense to continue training.
Let's make this more formal. The authors introduce the notion of a drfiting field as a way to model , so
where and , and . When , we want the drifting field to be 0. This notion of equilibrium motivates an update rule:
Here are the parameters of the model at iteration . The loss function is the mean-squared error of and :
We use a stopgrad since we want to freeze our target and move our current predicted samples towards it.
Designing the Drifting Field
Now how should we design ? Recall that we wish to find our In the paper, they give a sufficient (but not necessary) condition: make anti-symmetric. To see this, note that .
The paper considers drifting fields of the form:
where is a function describing interactions on sampled points from the target distribution and the current estimate of it. Here just needs to be 0 when .
The authors define fields
and decompose into a difference . Here and are normalization constants and , respectively. We can rewrite as follows:
The reason we can rewrite terms , into a combined expression is because the variables , are drawn separately, so their product can be written as an expectation over the product measure .
From this, it's immediately obvious that is anti-symmetric, so our training objective discussed earlier is well-defined. The kernel they used was
Implementation Details
We give a concrete implementation of the drifting field above:
def compute_drift_field(x_bd, ypos_bd, yneg_bd, temp: float = 0.05, eps: float = 1e-12):
"""
Computes the drift field V_pq(f(eps))
:param x_bd: [N, D]
:param ypos_bd: p, distribution of the data. [N_pos, D]
:param yneg_bd: q, current distribution. [N_neg, D]
Note that the batch dimensions of the data and generated predictions
do not have to be the same.
Returns a [N, D] matrix representing a drift field.
"""
targets = jnp.concatenate([yneg_bd, ypos_bd], axis=0)
N_neg = x_bd.shape[0]
dist = cdist(x_bd, targets)
# since x_bd is the same as yneg_bd, mask self
dist = dist.at[:, :N_neg].add(jnp.eye(N_neg) * 1e6)
kernel = jnp.exp(-dist / temp)
normalizer = jnp.sum(kernel, axis=-1, keepdims=True) * jnp.sum(kernel, axis=-2, keepdims=True)
normalizer = jnp.sqrt(jnp.clip(normalizer, a_min=eps))
normalized_kernel = kernel / normalizer
K_neg, K_pos = jnp.split(normalized_kernel, [N_neg,], axis=1)
pos_coeff = K_pos * jnp.sum(K_neg, axis=-1, keepdims=True)
V_pos = pos_coeff @ ypos_bd
neg_coeff = K_neg * jnp.sum(K_pos, axis=-1, keepdims=True)
V_neg = neg_coeff @ yneg_bd
return V_pos - V_negTo see how this can be written in the form , observe that and
Combining the two, we get that
which is exactly the form that we wanted. Here it's clear that and represent and respectively.
What about the normalization terms and . When we compute , we bake in the normalization by summing across the concatenated dimension and dividing by that constant. We also normalize over the batch dimension as it improved training dynamics.
Experiments on Toy Distributions
A JAX implementation of the above can be found here:
I was able to train the model on the toy distributions (chessboard, spiral). After 2.5k iterations, the drifting model produced some pretty neat results.
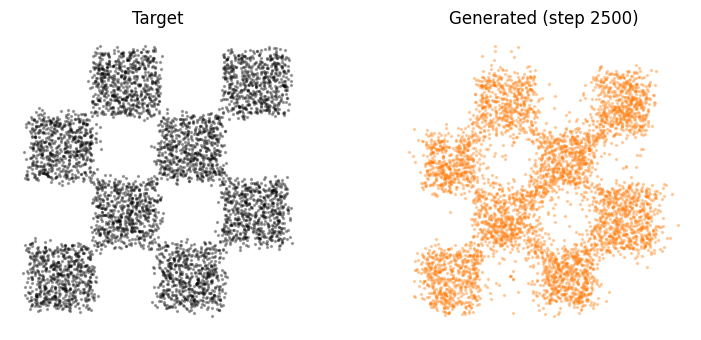
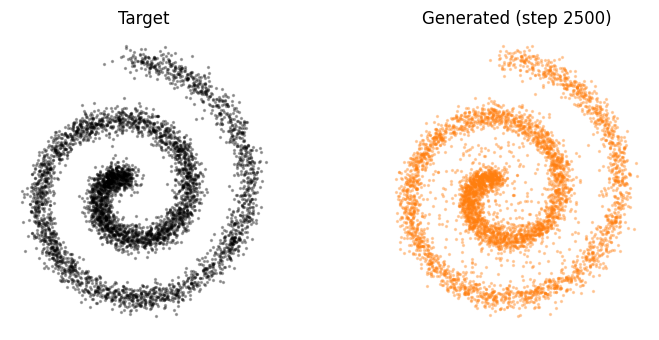
Extending this to Actual Large-Scale Image Datasets
Much like other work such as Diffusion Transformers, this method can work on encoded features instead of raw pixels. Let be a feature encoder. We can define our new loss as:
where . The update rule is changed similarly.